Categoría: Bases de datos clínicas
La minería y explotación de datos
Publicado en parte en la revista AMF
Es casi un mito en el mundo del data mining o Big Data la anécdota contada por el periodista Charles Duhigg en The New York Times, de cómo la cadena americana de supermercados Target, “adivinaba” que sus clientas estaban embarazadas, incluso antes que sus propios familiares. Esta magia estadística se basaba en asignar a cada cliente femenina posibilidades de embarazo de acuerdo a sus hábitos de compra. La cadena poseía millones de este tipo de datos y resultaba fácil, aparentemente, crear un modelo donde se asignaba una probabilidad a un resultado (por ejemplo, el embarazo), en tanto en cuanto se conocían los productos que las mujeres embarazadas compraban antes, y al inicio del embarazo. Además, y aplicando el teorema de Bayes, la probabilidad de la hipótesis variaba, y se hacía más o menos potente a medida que obtenía más información de compra de productos.
Por otro lado, Timothy Libert, público hace un año en el BMJ (3) un artículo, resumen de uno anterior, donde se alertaba sobre la información que proporcionamos cuando realizamos búsquedas sobre salud en los buscadores habituales, o cuando visitamos páginas web sanitarias. Muchas de las direcciones de páginas que visitamos, contienen información específica relacionada con alguna enfermedad, tratamiento o síntoma médico. Como quiera que estas URls se almacenan en servidores propios y de terceros, el análisis de estas direcciones puede revelar a los dueños de estos servidores información sanitaria sensible, que se liga facilmente al usuario del ordenador.
Tomando la base de estos dos mimbres podemos explicarnos el artículo publicado, en una revista no muy familiar para los médicos de familia, y que he conseguido una vez más gracias a mi bibliotecaria favorita. Su autores son investigadores de Microsoft y se titula Detección de adenocarcinoma pancreático utilizando señales provenientes de los registros de búsquedas web: Estudio de viabilidad y resultados.
 En este trabajo los autores construyen un modelo utilizando métodos estadísticos predictivos complejos, y una cantidad enorme de datos que se recogen de la actividad en la red de los pacientes. Actúan así bajo la presunción de que esta actividad puede dar pistas sobre enfermedades todavía no diagnosticadas, en este caso: adenocarcinoma de páncreas. En el articulo se analizaron registros de búsqueda a gran escala de personas que hubieran buscado información en el buscador Bing sobre adenocarcinoma de páncreas y/o una serie de síntomas y factores de riesgo que se producen en ese tipo cáncer. Por otro lado, se identificó un subgrupo de pacientes que habían buscado sobre cáncer pancreático, y que, gracias a que realizaban búsquedas explicitas, se había determinado que padecían esa enfermedad (experiential searches o búsquedas que son altamente sugestivas de un diagnóstico de adenocarcinoma de páncreas por un profesional)
En este trabajo los autores construyen un modelo utilizando métodos estadísticos predictivos complejos, y una cantidad enorme de datos que se recogen de la actividad en la red de los pacientes. Actúan así bajo la presunción de que esta actividad puede dar pistas sobre enfermedades todavía no diagnosticadas, en este caso: adenocarcinoma de páncreas. En el articulo se analizaron registros de búsqueda a gran escala de personas que hubieran buscado información en el buscador Bing sobre adenocarcinoma de páncreas y/o una serie de síntomas y factores de riesgo que se producen en ese tipo cáncer. Por otro lado, se identificó un subgrupo de pacientes que habían buscado sobre cáncer pancreático, y que, gracias a que realizaban búsquedas explicitas, se había determinado que padecían esa enfermedad (experiential searches o búsquedas que son altamente sugestivas de un diagnóstico de adenocarcinoma de páncreas por un profesional)
Una vez identificados estos dos grupos se obtuvieron retroactivamente, los registros de la actividad de búsqueda para examinar los patrones de síntomas y factores de riego, que son expresados como búsqueda. A partir de estos se construyeron clasificadores estadísticos que predecían la aparición futura de cáncer de páncreas. Es decir, las consultas históricas originaban patrones a partir de señales observadas en los registros de búsqueda que permitían predecir el futuro de aparición de experiential searches, pudiéndose identificar de 5% a 15% de los casos, preservando al mismo tiempo tasas extremadamente bajas de falsos positivos. Los autores concluyen que las señales (o búsquedas sobre determinados síntomas y factores de riego) en los registros de búsquedas web muestran las posibilidades de predicción de un diagnóstico, cercano en el tiempo de adenocarcinoma de páncreas; a partir de combinaciones de señales temporales sutiles reveladas en las consultas de los buscadores.
La verdad es que no hemos entendido muy bien los métodos estadísticos que describen, muy alejados de los que se utilizan en medicina, para conformar el modelo, tampoco seriamos capaces de explicarlo en términos de una prueba de cribado, pero estas conclusiones dan un poco vértigo y nos hablan del valor real y aplicaciones beneficiosas del data mining en sanidad por encima de tanta palabrería sin base sobre el Big Data.
indicacion > prescripción
Las soluciones más simples suelen ser las más eficaces y correctas. La simplicidad sin embargo se muestra elusiva cuando se busca y se hace mucho menos probable cuando los que la persiguen aumentan en número y capacidad de decisión. La informatización se puede implantar para agilizar procesos burocráticos tediosos o automatizar rutinas, pero tambien para la innovación mediante nuevas funcionalidades y facilitando el balance entre beneficios y cargas de trabajo en tareas de un gran valor añadido potencial.
 Un grupo de autores norteamericanos conjuga estas dos premisas en un artículo de perspectiva publicado en el NEJM esta semana. Proponen incorporar la “indicación” (o razones que motivan su uso) en la receta o cualquier tipo de orden de dispensación. Esta medida tan simple es poco seguida. Las recetas médicas oficiales incluyen en la hoja de instrucciones a pacientes, un apartado para el Diagnóstico, pero rara vez se cumplimenta. Los informes hospitalarios y de salud se disponen de tal forma que se exponen una lista de diagnósticos y una lista consecutiva de medicamentos, sin que en ningún caso se correlacione una lista con la otra. En la era de la receta electrónica añadir la indicación en la prescripción de medicamentos es oportuna y poco costosa, permitiría una prescripción basada en la indicación que ofrecería ventajas tales como:
Un grupo de autores norteamericanos conjuga estas dos premisas en un artículo de perspectiva publicado en el NEJM esta semana. Proponen incorporar la “indicación” (o razones que motivan su uso) en la receta o cualquier tipo de orden de dispensación. Esta medida tan simple es poco seguida. Las recetas médicas oficiales incluyen en la hoja de instrucciones a pacientes, un apartado para el Diagnóstico, pero rara vez se cumplimenta. Los informes hospitalarios y de salud se disponen de tal forma que se exponen una lista de diagnósticos y una lista consecutiva de medicamentos, sin que en ningún caso se correlacione una lista con la otra. En la era de la receta electrónica añadir la indicación en la prescripción de medicamentos es oportuna y poco costosa, permitiría una prescripción basada en la indicación que ofrecería ventajas tales como:
- Mejora en la seguridad del paciente y evitar errores de medicación
- Aumento del conocimiento sobre los tratamientos que toma y “para que” los toma, con una consiguiente mejora del cumplimiento terapéutico.
- Facilitar la accion de sistemas inteligentes de ayuda a la prescripción.
- Amplia el conocimiento de los tratamientos entre el equipo de profesionales sanitarios que en un momento determinado interactúan con el paciente
- Simplifica el proceso de conciliación de la medicación en las transiciones asistenciales
- Contribuye al conocimiento de la efectividad, idoneidad y usos fuera de indicación de los medicamentos y sus resultados.
Como objeciones se apunta en el artículo el problema de la confidencialidad, el aumento de la carga de trabajo (minimizado con un buen e “inteligente” sistema informático), la dificultad de asignar “indicaciones” y las clasificaciones utilizadas, así como el necesario respeto a la autonomía y capacidad de elección de los médicos. Como los americanos no son dados al hablar por hablar, ya han presentado un proyecto suficientemente financiado para favorecer este cambio hacia la prescripción basada en la indicación
En nuestro país y en particular en atención primaria la implantación de esta sencilla medida tendría al menos dos beneficios adicionales. Uno es el aumento de la calidad en la cumplimentación de las historias clínicas electrónicas, autenticos patatales de episodios y prescripciones. Resulta curioso que mientras en el artículo se aboga por ligar en los registros electrónicos la indicación a la prescripción, en nuestra historia clínica electrónica, gracias la clarividencia de sus creadores, esta tarea ya es obligatoria desde el principio.
Otra es la creación de “auténticos” indicadores de calidad de la prescripción en lugar del amasijo informe de números que pueblan y divierten las hojas de cálculo de nuestros directivos y farmacéuticos de área.
Gordon D. Schiff, Enrique Seoane-Vazquez, Adam Wright. Incorporating Indications into Medication Ordering — Time to Enter the Age of Reason. N Engl J Med 2016; 375:306-309 DOI: 10.1056/NEJMp1603964
Consultas de cristal
Publicado en 7DM nº 869, Junio–Julio 2016


Hace justo un año, durante la campaña electoral de las municipales, Esperanza Aguirre, candidata popular a la alcaldía de Madrid, se vio sorprendida cuando un medio digital sacó a la luz pública su declaración de la renta del año anterior. Como ella señaló, los datos solo podían haber salido del Ministerio de Hacienda, y en este sentido fue la demanda que presentó ante la fiscalía reclamando conocer cómo habían podido hacerse públicos. Meses más tarde, otra política, esta vez de signo contrario, Anna Gabriel, también se sobresaltó cuando, en pleno proceso negociador por el gobierno de la Generalitat de Cataluña, una cadena de televisión nacional emitió un vídeo donde se la veía tomando un avión del gobierno venezolano, junto a otros políticos de izquierda y del entorno de ETA, con destino a Venezuela para asistir a un foro político que se celebraba en Caracas.
La diputada autonómica, al saberse la noticia, planteó la posibilidad de que estas imágenes las pudieran haber filmado cuerpos de seguridad españoles y mostró su preocupación sobre la posibilidad de que existan ficheros ilegales y seguimiento a activistas políticos.
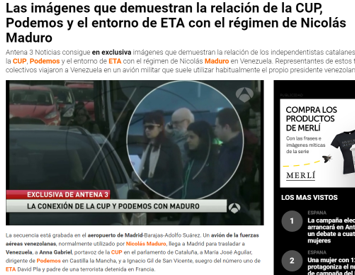
En ambos casos, ninguna de las dos políticas había cometido un hecho delictivo, ni siquiera reprobable desde un punto de vista moral o político: ganar dinero, siempre que se haga de forma honesta y legal, no es ningún pecado; colaborar y trabajar con la revolución bolivariana tampoco. Por lo demás, no eran situaciones ocultas o desconocidas totalmente. Sin embargo, estos dos escenarios, aireados por los medios de comunicación en dos momentos concretos, causaron un problema a sus protagonistas. La propia Esperanza Aguirre no se cansa de afirmar que a ella le costó las elecciones y Anna Gabriel puso en apuros el acuerdo de su partido para la elección de presidente de la Generalitat.
Pero, con todo, el principal problema es que esta información no estaba en manos de los medios de comunicación, sino en las del Estado, y estos medios llegaron a ellos por una filtración activa e interesada por parte de alguien que, si los tenía, era en función de sus tareas como funcionario estatal. Este es el mismo estado que obtiene y almacena datos e información sobre muchas de nuestras actividades; incluidos, no lo olvidemos, nuestros datos médicos y sanitarios. La recogida masiva de datos de una importante parte de la población, gracias a una red completa de vigilancia, es lo que se conoce con el término metafórico alemán de Gläserner Mensch (hombre de cristal o transparente por analogía con los modelos anatómicos transparentes del museo de ciencias naturales de Dresde). Es una vieja ilusión de los estados totalitarios, para tener controlada a su población, y su paradigma puede ser la policía secreta de la Alemania socialista que le puso el nombre. Desaparecida la Stasi, y con el advenimiento de la realidad digital, otros estados autocráticos, o no, así como empresas privadas u organizaciones no gubernamentales, toman el relevo en esta vigilancia masiva. Esta se justifica a menudo como una forma de combatir el terrorismo o proteger la seguridad nacional, o simplemente elevar la seguridad de los ciudadanos; pero también se pone de manifiesto la capacidad de intromisión en la privacidad de los individuos y el potencial real de sobrepasar límites morales y legales. En el campo sanitario, el temor se relaciona con la posibilidad de que datos sensibles personales sean fácilmente accesibles a cualquier persona con acceso al sistema y su uso para tareas distintas de la ayuda y cuidado del paciente.

Recoger datos está en el mismo corazón de la asistencia clínica; si estos datos se digitalizan y se ponen en red, se facilitan muchas de las actividades relacionadas con la atención al paciente. Muchos de los datos sanitarios se recogen con las mejores de las intenciones: los profetas de la innovación nos convencen de que se podrían utilizar en investigación clínica, gestión de los servicios sanitarios o salud pública. Pero, al igual que se intuyen sus ventajas, también se descubren zonas oscuras. Demasiadas personas acceden a los registros clínicos, muchas veces sin una causa justificada. Disponer de la historia clínica completa de una persona es un valioso tesoro que se puede utilizar de muy diversas maneras, no relacionadas precisamente con la salud.
Las medidas legales y logísticas encaminadas a proteger estos datos son a todas luces insuficientes, y es que no estamos hablando de que en un momento determinado alguna persona acceda a unos datos concretos. Hablamos de nuestra ignorancia sobre la cantidad y valor de la información digital que se produce diariamente de forma automática. Con estos datos se pueden generar perfiles que revelan sobre nosotros mismos, aspectos que no siempre quisiéramos que fueran descubiertos. Lo llaman, entre otros nombres, Big Data y su potencial benéfico es apreciable, pero ¿apreciable para quién? ¿Para qué y quién está utilizando estos «data»? El problema es que la existencia misma de esa información nos hace muy vulnerables, y lo hace de una manera que no podemos ni anticipar ahora mismo.
Trabajamos en consultas de cristal.
No nos saltemos escalones
En colaboración con Miguel Angel Mañez @manyez
¿Qué queremos decir cuando decimos que no pasemos al 2.0 o 3.0 sin haber pasado adecuadamente por el 1.0?
 Vamos a explicarlo, eso sí en su parte tecnológica y con ejemplos reales, la deontológica y sentimental la dejamos para otro día.
Vamos a explicarlo, eso sí en su parte tecnológica y con ejemplos reales, la deontológica y sentimental la dejamos para otro día.
No nos saltemos escalones, antes de posturear con lo 2.0 y sus secuelas convendría que la sanidad española en su cojunto y sobre todo la administracion sanitaria publica, iniciara de una vez una política adecuada de información y comunicación, que se debería ir concretando en:
- Creación de una sede web de información para pacientes rigurosa, comprensiva, ilustrada, actualizada y adaptada a varios niveles de alfabetización sanitaria.
Ejemplo: MEDLINE –PLUS
- Acceso sin restricciones a Internet de alta velocidad desde cualquier consulta y recinto sanitario para profesionales (al menos) y pacientes.
Ejemplo: Después de mucho dudar servicios públicos de transportes, hoteles, etc y otros están dando este servicio
- Acceso rápido, gratuito y sin cortapisas a fuentes de información necesaria para la práctica de una toma de decisiones informada y basada en la evidencia
Ejemplo: La suscripción del Ministerio de Sanidad a UptoDate para toda España
- Observatorio institucional dinámico y moderno sobre información y comunicación sanitaria orientada al ciudadano, que dé respuesta inmediata a informaciones de los mass y social media relacionadas con la salud, problemas con la prestación de servicios, crisis sanitarias, etc.
Ejemplo: Behind the Headlines NHS
- Portales sanitarios donde los servicios de salud expusieran toda la información que un paciente pudiera necesitar cuando se “enfrenta” al sistema de salud. La información que debería contener iría desde directorios de profesionales, horas de consulta, formas de contacto, cartera de servicios, hasta localización y servicios de atención información rápida on-line.
Ejemplo: Portal de pacientes en Dinamarca.No tenemos ni idea de danés pero lo que cuenta su CEO en esta entrevista es puro sentido común.
- Acceso a datos sanitarios por parte del usuario y profesionales de tal forma que cualquier paciente o profesional pueda acceder on line a todos los datos sanitarios necesarios, con las únicas restricciones que imponga la una seguridad bien entendida. El acceso se debe poder realizar desde cualquier lugar a asegurando la interoperabilidad de los sistemas sanitarios.
Ejemplos: el futuro que se lleva anunciando desde hace años (10 por lo menos) con la introducción e implantación de la fantasmagórica Historia Clínica Digital del Sistema Nacional de Salud (HCDSNS)
- Garantizar la confidencialidad y privacidad de los datos sanitarios de forma exquisita. Para que estos datos estén en la red se debe contar con la autorización previa, explícita y documentada del usuario, el cual tendrá derecho a cancelar la información cuando crea oportuno y a conocer de forma instantánea, quien y cuando accede a su datos. Los permisos de acceso serán restrictivos, temporales, revocables y limitados a la información necesaria para la toma de decisiones en aspectos concretos de la atención sanitaria.
Ejemplo: “los pacientes pueden ver qué profesional de salud ha consultado su expediente” En teoría el modelo español incluye, pero desde que la estrategia de la HCDSNS lleva en marcha y pocos sitios han cumplido los plazos.
- Base de datos compresiva sobre medicamentos actualizada, gratuita, gráfica y fácil de utilizar que incluya información de valor añadido (precios, alertas, toxicidad, interacciones, etc.) con versiones para profesionales y público en general
Ejemplos: aunque mejorable la página web y app de IDoctus o Medimecum
- Comunicación entre niveles profesionales y médico-paciente mediante aplicaciones electrónicas (correo, mensajería, chats, etc.) instalados en plataformas que aseguren la confidencialidad y de titularidad pública.
Ejemplo: Programa de comunicación telemática con el centro de salud del Servicio Murciano de Salud . Además se han intentado iniciativas muy interesantes pero en general han fenecido por carecer de apoyo institucional en su desarrollo, véase este post de hace seis años, que se complementa con esta presentación.
Dos formas de obtener conocimiento: Big Data y Medicina Basada en la Evidencia
Como comentábamos en el anterior post, la revista Annals of Internal Medicine publica un breve artículo de opinión sobre big data y medicina basada en la evidencia, resumen de la intervención del autora en el 3rd Annual Cochrane Lecture, de octubre de 2015 (vídeo disponible)
El artículo cuya traducción «libre» al español se puede encontrar aquí expone que aunque los «Big Data» parecen ser una alternativa poderosa y tentadora a la medicina basada la evidencia (como algunos atolondrados gurús sugieren) este enfrentamiento se cierra en cuanto comprendemos que tener datos no es igual a conocimiento.
Como se comenta en el artículo, lo que se ha venido a denominar Big Data o Datos masivos es un concepto que hace referencia a la acumulación de grandes cantidades de datos y a los procedimientos usados para encontrar patrones repetitivos dentro de esos datos. En medicina, la actividad diaria genera enormes cantidades de datos recogidos por los médicos en las historia clínica electrónica, a los que se puede añadir los datos generados de la monitorización (Quantified self) con los nuevos sensores móviles (wearables) o los presentes en las redes sociales. Sin olvidar la clásica fuente de información de la literatura médica. Análisis y sistemas como Watson de IBM están ya fusionando datos genómicos, literatura médica publicada, y datos de la HCE para guiar, por ejemplo, tratamientos contra el cáncer.
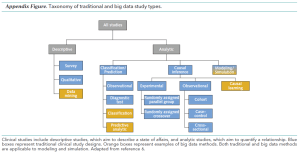 Gracias a Big Data el ritmo, las fuentes de datos, y los métodos para generar pruebas médicas cambian radicalmente pero no hay que intentar separar la investigación clínica de estos métodos, ni debemos porque la medicina basada en la evidencia y los big data tienen fortalezas complementarias. Como se ve en la figura, los métodos de big data puede incluirse en una taxonomía de los tipos de estudios que es familiar a la mayoría de los investigadores clínicos. Pueden además ofrecer una ampliada potencia a otros tipos de estudios analíticos.
Gracias a Big Data el ritmo, las fuentes de datos, y los métodos para generar pruebas médicas cambian radicalmente pero no hay que intentar separar la investigación clínica de estos métodos, ni debemos porque la medicina basada en la evidencia y los big data tienen fortalezas complementarias. Como se ve en la figura, los métodos de big data puede incluirse en una taxonomía de los tipos de estudios que es familiar a la mayoría de los investigadores clínicos. Pueden además ofrecer una ampliada potencia a otros tipos de estudios analíticos.
En resumen la medicina basada en la evidencia necesita la potencia de cálculo de los big data y estos el rigor epistemológico de la MBE.
Big Data, MBE ruido y nueces
Big Data por todos lados. Cualquiera que siga las tendencias actuales en salud habrá oído hablar o leído algo sobre los big data. Se ha oído tanto, que ya es un lugar casi común al igual que lo fue en su momento en otras disciplinas y campos (la salud, o mejor dicho los “adelantados” sanitarios siempre van algo retrasadillos). Un fenómeno, este de los big data del que, como comprobé en una serie de conferencias de la fundación Telefónica, muchos (demasiados) hablan, pocos conocen en profundidad, y muchos menos, lo utilizan con provecho.Vamos como otras cosas que luego trasmutan en burbuja tecnológica.

Hello World! | Christopher Baker Instalación audiovisual alimentada por fragmentos de miles de diarios personales grabados en vídeo y colgados en internet
La capacidad para aprender de datos e información situados en formatos y lugares inaccesibles hasta ahora, e incluso poder replicar el conocimiento tácito, es una vieja aspiración de la gestión del conocimiento que se torna en realidad con la aparición las historias clínicas digitales, la capacidad de manejar gran cantidad de datos de forma ágil y rápida (Big Data), el aprendizaje automático y la inteligencia artificial.
Pero de ahí a hablar como hace algunos gurus patrios de nuevo paradigma que va cambiar radicalmente la forma de practicar y tomar las decisiones en medicina, hay un trecho importante que intentare explicarme (si explicarme porque todavía no lo entiendo del todo, como para explicarlo a los demás) algún día. Todavía no sé cómo hincarle el diente a estos nuevos fenómenos computacionales que mezclan un masa de datos informe con unas gotas de sabiduría de las multitudes, esencia de smartmob , un chorrito de robótica y otro de inteligencia artificial, y todo ello en un gran molde de ignorancia sobre los efectos de esta pócima.
Sin duda una de las más atractivas y a la vez osadas aseveraciones de estos profetas es la superación (sin piedad, ni concesiones) de la medicina basada en la evidencia por una medicina generadora de evidencias (sic), demostrando que desconocen lo sustantivo de las dos herramientas. Otros investigadores más prudentes e informados abogan por incluir el portento Big Data en una importante (pero una mas) de las posibles fuentes de evidencias o pruebas. Entre ellos está Ida Sim, profesora de la UCSF School of Medicine que tanto en sus intervenciones en un coloquio Cochrane (ver vídeo más abajo) como en un artículo breve que resume esta intervención publicado en el Annals of Internal Medicine hace unos días (mañana aparecerá en este blog la traducción) pone de manifiesto la complementariedad de ambas tendencias, y su espléndido futuro siempre que sea conscientes de sus limitaciones y fortalezas.
La edad relativa o el efecto guarín*
Como explicábamos en un post de hace mas de un año, la diferencia de edad cronológica de sujetos seleccionados entre los de un mismo rango etario, es lo que se llama edad relativa. Cuando esta diferencia tiene consecuencias sobre una determinada característica o variable, se le denomina efecto de la edad relativa (relative age effect) que podríamos renombrar como efecto guarin*.
Este efecto se ha visto en varios campos y disciplinas desde el deporte, hasta la salud mental. También se ve (y para mal) en una enfermedad, el trastorno por déficit de atención/hiperactividad (TDAH) de diagnóstico exclusivamente clínico, sobre el que planea la preocupación de daños potenciales de un sobrediagnóstico y prescripción excesiva.
En el número de diciembre de la revista Medicina Clínica se publica un artículo: Edad relativa de los niños en clase y tratamiento farmacológico del trastorno por déficit de atención/ hiperactividad. En este estudio poblacional en un departamento de salud de la provincia de Castellón, se muestra que los niños con menor edad relativa que sus compañeros de clase tienen una mayor probabilidad de ser tratados con metilfenidato y/o atomoxetina. Se utilizaron y confrontaron dos bases de datos: un sistema de información poblacional, de donde se extrajeron las fechas de nacimiento (mes y año), y un sistema de gestión farmacéutica ligado a la historia clínica electrónica, de donde se obtuvieron las prescripciones de fármacos autorizados para el tratamiento del TDAH.
 En el análisis bivariante, la prevalencia de tratados se incrementa con la edad y con el mes de nacimiento, desde el 0,79% para los nacidos en el mes de enero, al 2,24% para los nacidos en diciembre. El sexo tambien influyo, el gradiente de tratamiento en relación con el mes de nacimiento fue significativo en los niños (p < 0,001), pero no en las niñas (p = 0,059). Los niños que nacieron en diciembre tuvieron casi 3 veces más probabilidades de estar en tratamiento para el TDAH que los nacidos en enero (OR: 2,81; IC 95%: 1,53-5,16).
En el análisis bivariante, la prevalencia de tratados se incrementa con la edad y con el mes de nacimiento, desde el 0,79% para los nacidos en el mes de enero, al 2,24% para los nacidos en diciembre. El sexo tambien influyo, el gradiente de tratamiento en relación con el mes de nacimiento fue significativo en los niños (p < 0,001), pero no en las niñas (p = 0,059). Los niños que nacieron en diciembre tuvieron casi 3 veces más probabilidades de estar en tratamiento para el TDAH que los nacidos en enero (OR: 2,81; IC 95%: 1,53-5,16).
Los estudios que muestran este efecto, lo explican por el grado de desarrollo menor de los niños nacidos más tarde dentro de un grupo con un rango de edades determinado. En edades en que unos meses de diferencia pueden ser importantes este hecho es especialmente notorio y observable. Si a esto se le añade, el caso del deporte es un buen ejemplo, una selección y un entrenamiento diferenciado, la desventaja inicial se ira agrandando, hasta hacerse muy manifiesta. Una de las soluciones para minimizar este efecto guarín seria una estrategia más flexible en la incorporación a la escolarización obligatoria, como es el caso de países escandinavos donde los padres tienen un cierto margen para escolarizar a sus hijos, y sobre todo ser conocedores y tener en cuenta este efecto en la educación y desarrollo de los niños.
En el caso del TDAH se argumenta, con demostración empírica, que los profesores, por comparación con sus compañeros de clase mayor edad relativa, interpretan los comportamientos de estos niños más inmaduros, como típicos de TDAH. Los autores del artículo que reseñamos apuntan que los clínicos deberían ser muy prudentes con el etiquetado y tratamiento de los niños de 6-9 años que han nacido en los últimos meses del calendario para evitar el sobrediagnóstico de TDAH y la utilización excesiva de fármacos con potenciales efectos adversos importantes.
* guarín. (De la onomat. guar, guarr de llamar al cerdo). 1. m. Último lechón nacido en una lechigada.
El conocimiento generado durante la práctica
El conocimiento generado durante la práctica irremisiblemente perdido.
 Sin contemplar la parte de conocimiento tácito, una fuente de conocimiento de incalculable valor es la que se genera durante la práctica cotidiana.
Sin contemplar la parte de conocimiento tácito, una fuente de conocimiento de incalculable valor es la que se genera durante la práctica cotidiana.
Diariamente millares de médicos obtienen datos sobre casos y enfermedades similares, registran una cantidad ingente de información sobre el curso natural de las enfermedades o reacciones adversas a medicamentos, y consiguen millones de resultados de pruebas diagnósticas.
Dado el entorno en que se trabaja, dominado por el soporte papel, la tasa de re utilización de esta información y su capacidad para generar conocimiento es prácticamente nula.
La informatización plena de todos los procesos sanitarios administrativos y clínicos serían capaces de crear grandes bases de datos clínicas. La capacidad relacional de estas bases de datos y el diseño de programas específicos destinados a la extracción de datos permitirían obtener, en tiempo real, un flujo de información que generaría conocimiento y facilitaría la retroalimentación.
La insoportable levedad de la #e-health (I)
A la salud y todo lo que tiene que ver con ella, se le han adjuntado en los últimos años nuevos protagonistas. A los tradicionales como profesionales sanitarios, pacientes, administración sanitaria e industria farmacéutica, se han añadido nuevos invitados como son la industria de los dispositivos y las compañías de comunicación y tecnológicas.
Estas últimas han visto como su importancia como industria de servicios e innovación se ha incrementado con el desarrollo de las nuevas tecnologías de la información en la ciencia médica y en la práctica de cuidados a los pacientes. El controvertido modelo de crónicos ha dado alas a este modelo de negocio donde lo que se pretende es vender soluciones y servicios en el ámbito de las nuevas tecnologías aplicada a la sanidad.
 Si la coordinación y comunicación entre niveles asistenciales, servicios socio-sanitarios, profesionales y pacientes se considera como el eje fundamental de una buena asistencia a este paciente crónico (suponemos que también a los demás), estas pretendidas soluciones tecnológicas pasan también a ser primordiales.
Si la coordinación y comunicación entre niveles asistenciales, servicios socio-sanitarios, profesionales y pacientes se considera como el eje fundamental de una buena asistencia a este paciente crónico (suponemos que también a los demás), estas pretendidas soluciones tecnológicas pasan también a ser primordiales.
La comunicación entre profesionales y pacientes se ve adornada de tecnologías de la comunicación y aplicaciones móviles que permiten compartir información, al parecer vital, entre ambos actores. Es “vital” que los sistemas sanitarios y desvalidos pacientes (desvalidos por estar enfermos) gaste una cantidad ingente de dinero y energía para adaptarse a este modelo. En palabras de uno de sus expertos “es importante facilitar la utilización de estas herramientas en personas mayores» y “ los servicios de salud deben integrar estos sistemas cuanto antes»
La monitorización evolutiva de síntomas, signos y constantes (que no de sentimientos) facilita el desarrollo de mitos sanitarios emergentes como gestión de crónicos, salud electrónica, empoderamiento, calidad y seguridad y antiguos como prevención, promoción y educación. Lo que esta por ver es que demuestren su impacto en la salud en general, medida con términos tan prosaicos como mortalidad, morbilidad o bienestar.
Acceso a la historia clínica: ¿a favor o en contra?
No hay cama pa’ tanta gente publicado en El farmacéutico.Profesión y cultura
Por Rafael Bravo
La historia clínica es el registro en el que se plasma el devenir del paciente en el mundo sanitario. Dadas sus características, ha pasado de ser un instrumento meramente profesional a ser la parte fundamental de los sistemas de información y el lugar en que se recogen los deberes éticos y legales de los profesionales sanitarios e instituciones públicas.
Con los nuevos avances tecnológicos, a la historia clínica se le han añadido cualidades, en mi opinión impostadas, que añaden nuevas funciones pero también nuevos inconvenientes.
Estas son la unicidad y la ubicuidad.
Parece que ahora la historia debe ser única y omnipresente, de tal forma que pueda ser accesible a la mayor cantidad de personas posible. No debemos olvidar que estas dos condiciones son sobrevenidas por los alcances tecnológicos, y que a nadie se le habría ocurrido reivindicarlas en los tiempos en que la historia clínica se conformó como herramienta del quehacer médico.
Desde la intuición, sobre todo profana, es difícil no estar de acuerdo cuando alguien enumera las ventajas de que los datos sobre salud estén disponibles, en un único documento y desde cualquier sitio. Pero tras el relumbre tecnológico que realiza de forma fácil lo que antes era difícil está la reflexión…..
