Etiquetado: buscadores
Información , para qué?
Hace justo un mes la revista AMF anunciaba la creación de una página web por parte del ministerio de sanidad con el objetivo de proporcionar información sanitaria de calidad a pacientes y usuarios interesados. Era una broma. Lo que no es una broma es que la información sanitaria de calidad, en español y para pacientes, sigue siendo la gran olvidada de las políticas sanitarias del ministerio y de las consejerías de sanidad de las diferenes comunidades autonomas.
Se habla mucho de prescribir webs, de lo 2.0, de e-salud, de escuelas de salud, sin acordarse de los más básico, la materia prima. Esa materia prima informacional que es la que sale en las primeras posiciones (por su calidad y por acuerdos institucionales con las compañías tecnológicas) cuando los pacientes hacen búsqueda en internet a través de buscadores generales, la más frecuente y casi exclusiva forma de acercase a la información del usuario medio.
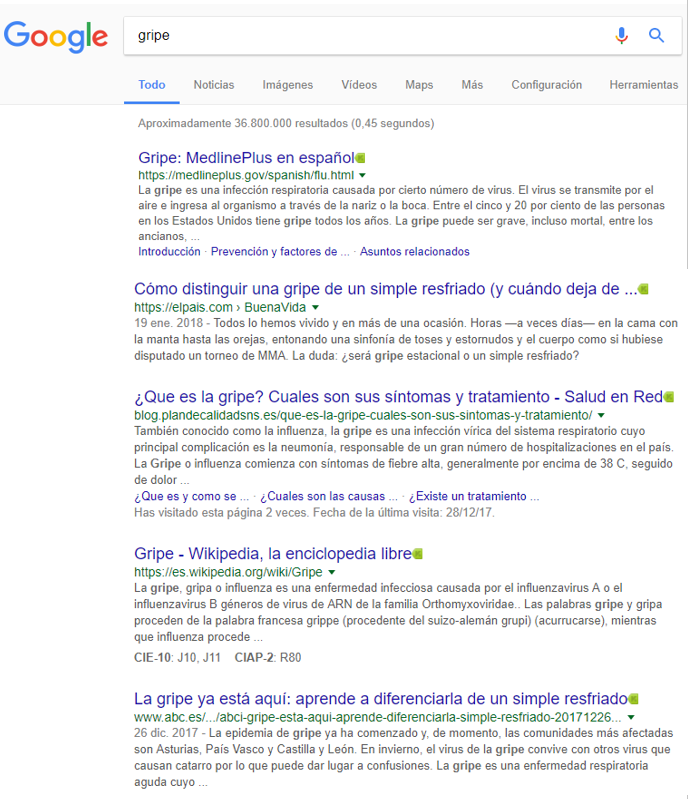
Es una pena que cuando un paciente español busca en Google.es por el termino gripe, obtenga esto:
y cuando lo hace en el Google.com americano, obtenga esto:
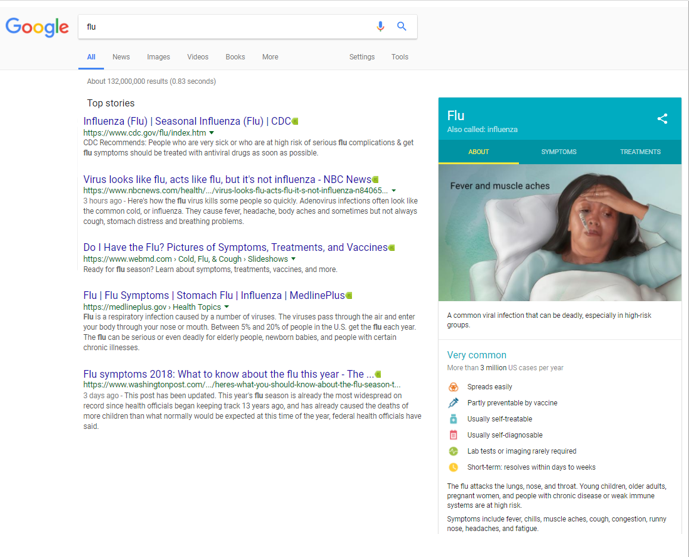
Véase la diferencia.
En el caso «español» el priner enlance es la entrada a un recurso (excepcional) del gobierno americano: Medline Plus, el segundo y quinto enlace son a páginas web de periodicos de tirada nacional. El cuarto enlace va a la definición de gripe de la Wikipedia y el tercer enlace a un blog de nombre equivoco – deberian darse cuenta en el MSSSI- y probablemente fraudulento con información que es un pastiche de varias y que recomienda por ejemplo de Jarabe de Cebolla, o el zumo de repollo y naranja como tratamiento de la gripe.
En el segundo caso o «caso americano» nos encontramos información de los Centros para el Control y la Prevención de Enfermedades el conocido CDC de Atlanta, la página web de una empresa de comunicacion general NBCnews, un enlace a una web sanitaria privada de calidad webMD , otro a Medline Plus y termina con la página web de un periodico.
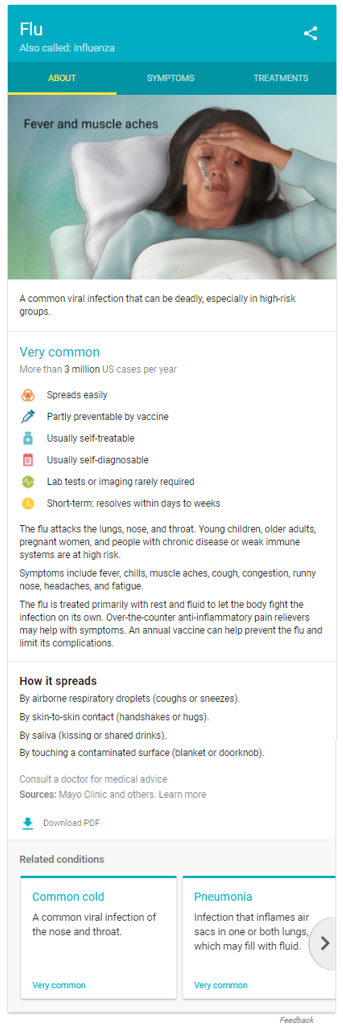
Llama la atencion un cuadro resumen de la izquierda, estos cuadros son un especie de «tarjetas» o gráfico de conocimiento – Google’s Healthcare Knowledge Graph– que Google introdujo -en algunos países- hace mas de dos años, en las busquedas de información médica sobre síntomas, tratamientos –medicamentos- y enfermedades. La informacion de esta tarjetas proviene de sitios web de muy buena calidad, y de los resultados de las búsquedas previas, revisada analizadas y seleccionadas por profesionales médicos, a la que se añade material grafico de ilustradores médicos autorizados.

La minería y explotación de datos
Publicado en parte en la revista AMF
Es casi un mito en el mundo del data mining o Big Data la anécdota contada por el periodista Charles Duhigg en The New York Times, de cómo la cadena americana de supermercados Target, “adivinaba” que sus clientas estaban embarazadas, incluso antes que sus propios familiares. Esta magia estadística se basaba en asignar a cada cliente femenina posibilidades de embarazo de acuerdo a sus hábitos de compra. La cadena poseía millones de este tipo de datos y resultaba fácil, aparentemente, crear un modelo donde se asignaba una probabilidad a un resultado (por ejemplo, el embarazo), en tanto en cuanto se conocían los productos que las mujeres embarazadas compraban antes, y al inicio del embarazo. Además, y aplicando el teorema de Bayes, la probabilidad de la hipótesis variaba, y se hacía más o menos potente a medida que obtenía más información de compra de productos.
Por otro lado, Timothy Libert, público hace un año en el BMJ (3) un artículo, resumen de uno anterior, donde se alertaba sobre la información que proporcionamos cuando realizamos búsquedas sobre salud en los buscadores habituales, o cuando visitamos páginas web sanitarias. Muchas de las direcciones de páginas que visitamos, contienen información específica relacionada con alguna enfermedad, tratamiento o síntoma médico. Como quiera que estas URls se almacenan en servidores propios y de terceros, el análisis de estas direcciones puede revelar a los dueños de estos servidores información sanitaria sensible, que se liga facilmente al usuario del ordenador.
Tomando la base de estos dos mimbres podemos explicarnos el artículo publicado, en una revista no muy familiar para los médicos de familia, y que he conseguido una vez más gracias a mi bibliotecaria favorita. Su autores son investigadores de Microsoft y se titula Detección de adenocarcinoma pancreático utilizando señales provenientes de los registros de búsquedas web: Estudio de viabilidad y resultados.
 En este trabajo los autores construyen un modelo utilizando métodos estadísticos predictivos complejos, y una cantidad enorme de datos que se recogen de la actividad en la red de los pacientes. Actúan así bajo la presunción de que esta actividad puede dar pistas sobre enfermedades todavía no diagnosticadas, en este caso: adenocarcinoma de páncreas. En el articulo se analizaron registros de búsqueda a gran escala de personas que hubieran buscado información en el buscador Bing sobre adenocarcinoma de páncreas y/o una serie de síntomas y factores de riesgo que se producen en ese tipo cáncer. Por otro lado, se identificó un subgrupo de pacientes que habían buscado sobre cáncer pancreático, y que, gracias a que realizaban búsquedas explicitas, se había determinado que padecían esa enfermedad (experiential searches o búsquedas que son altamente sugestivas de un diagnóstico de adenocarcinoma de páncreas por un profesional)
En este trabajo los autores construyen un modelo utilizando métodos estadísticos predictivos complejos, y una cantidad enorme de datos que se recogen de la actividad en la red de los pacientes. Actúan así bajo la presunción de que esta actividad puede dar pistas sobre enfermedades todavía no diagnosticadas, en este caso: adenocarcinoma de páncreas. En el articulo se analizaron registros de búsqueda a gran escala de personas que hubieran buscado información en el buscador Bing sobre adenocarcinoma de páncreas y/o una serie de síntomas y factores de riesgo que se producen en ese tipo cáncer. Por otro lado, se identificó un subgrupo de pacientes que habían buscado sobre cáncer pancreático, y que, gracias a que realizaban búsquedas explicitas, se había determinado que padecían esa enfermedad (experiential searches o búsquedas que son altamente sugestivas de un diagnóstico de adenocarcinoma de páncreas por un profesional)
Una vez identificados estos dos grupos se obtuvieron retroactivamente, los registros de la actividad de búsqueda para examinar los patrones de síntomas y factores de riego, que son expresados como búsqueda. A partir de estos se construyeron clasificadores estadísticos que predecían la aparición futura de cáncer de páncreas. Es decir, las consultas históricas originaban patrones a partir de señales observadas en los registros de búsqueda que permitían predecir el futuro de aparición de experiential searches, pudiéndose identificar de 5% a 15% de los casos, preservando al mismo tiempo tasas extremadamente bajas de falsos positivos. Los autores concluyen que las señales (o búsquedas sobre determinados síntomas y factores de riego) en los registros de búsquedas web muestran las posibilidades de predicción de un diagnóstico, cercano en el tiempo de adenocarcinoma de páncreas; a partir de combinaciones de señales temporales sutiles reveladas en las consultas de los buscadores.
La verdad es que no hemos entendido muy bien los métodos estadísticos que describen, muy alejados de los que se utilizan en medicina, para conformar el modelo, tampoco seriamos capaces de explicarlo en términos de una prueba de cribado, pero estas conclusiones dan un poco vértigo y nos hablan del valor real y aplicaciones beneficiosas del data mining en sanidad por encima de tanta palabrería sin base sobre el Big Data.
NNTs y Mednar

El NNT o número necesario a tratar es el reciproco de la Reducción de Riesgo absoluto, es un valor o indicador específico para cada tratamiento. Describe la diferencia entre un tratamiento activo y un control (placebo u otro tratamiento) en lo que se refiere a lograr un resultado clínico concreto (Wikipedia).
Hay personas que piensan que el NNT es un poderos metodo para mostar las difrencias que consigue un tratamiento, asi como para comparar la eficacia de diversos tratamientos y el esfuerzo que hay que conseguir para lograr un determiando efecto. Por esa razon publican esta completa página llena de buenos recursos y mejor información- The NNTs. Ensus propia palabras:
Hay una forma de entender lo que la medicina moderna tiene que ofrecer a los pacientes individuales. Hay un simple concepto en estadística llamado el «número necesario a tratar», o, para abreviar el ‘NNT. El NNT ofrece una medición del impacto de un medicamento o tratamiento mediante la estimación del número de pacientes que necesitan ser tratados con el fin de obtener un impacto en una persona. El concepto es estadístico, pero intuitivo, ya que sabemos que no todo el mundo se beneficia de una medicina o intervención – algunos se benefician, algunos se ven perjudicados, y algunos no se ven afectados. El NNT nos dice cuántos hay de cada uno.

Mednar es un buscador especial que utiliza otros motores de búsqueda para obtener resultados de alta calidad. Los presenta prácticamente en tiempo real una vez que ha recopilado, clasificado y omitido los duplicados
La verdad sobre TRIP
Con la nueva versión de Tripdatabase se ha cambiado el subtitulo de manera afortunada, en mi opinión . Del Turning Reserch Into Practice que conformaba el nombre de TRIP, al más apropiado Clinical Search Engine, ya que si algo es TRIP es una herramienta de búsqueda para clínicos, diseñada de tal forma que permita a los profesionales sanitarios identificar rápidamente las pruebas o evidencias de mejor calidad para la toma de decisiones en la práctica clínica.
 La versión española, llamada Excelencia clínica, ¡cielos! ¡qué horror de nombre! Aunque se autocalifica como un metabuscador, no lo es. En esto de Internet, las definiciones y nomenclaturas son variables y cambiantes, pero lo que de forma generalizada se entiende como metabuscadores (o también multi-buscadores) son aquellos motores de búsqueda que, no teniendo una base de datos propia, buscan la información utilizando otros motores de búsqueda e incluso índices, combinando los resultados de la búsqueda en esos buscadores. Como ejemplos de multi-buscadores en medicina podemos destacar el metabuscador de Science Roll o el viejo OmniMedicalSearch.
La versión española, llamada Excelencia clínica, ¡cielos! ¡qué horror de nombre! Aunque se autocalifica como un metabuscador, no lo es. En esto de Internet, las definiciones y nomenclaturas son variables y cambiantes, pero lo que de forma generalizada se entiende como metabuscadores (o también multi-buscadores) son aquellos motores de búsqueda que, no teniendo una base de datos propia, buscan la información utilizando otros motores de búsqueda e incluso índices, combinando los resultados de la búsqueda en esos buscadores. Como ejemplos de multi-buscadores en medicina podemos destacar el metabuscador de Science Roll o el viejo OmniMedicalSearch.
Por el contrario, un buscador federado, en el que se encuadra más propiamente TRIP, es un motor de búsqueda que proporciona, acceso, a través de una sola página, a toda una serie de recursos electrónicos que previamente han sido integrados en ella. Permite buscar en recursos presentes en internet y, por tanto, localizables con buscadores tradicionales, pero también documentos localizados en bases de datos, portales, catálogos, repositorios y otros recursos.
Un ejemplo general es el buscador 060, iniciativa del gobierno de España encaminada a facilitar al ciudadano la localización de la información publicada en el conjunto de los portales y sedes web de la administración. Los usuarios que utilizan este servicio obtienen una respuesta no solo del organismo al que están consultando, la web de un ministerio concreto, por ejemplo, sino también del resto de las administraciones afiliadas.
En medicina, el mejor ejemplo es TRIP que se inició hace doce años como respuesta a la necesidad de facilitar y acelerar la búsqueda de información médica basada en la evidencia dispersa por varios sitios web.
dr socrates
 Con un marcado enfoque británico en los resultados y utilizando la tecnología de búsqueda y de agrupación de los resultados por clúster o grupos relacionados de Vivísimo este nuevo buscador ofrece una buen solución para encontrar recursos útiles y relevantes cuando buscamos información médica ya sea como usuarios o como profesionales
Con un marcado enfoque británico en los resultados y utilizando la tecnología de búsqueda y de agrupación de los resultados por clúster o grupos relacionados de Vivísimo este nuevo buscador ofrece una buen solución para encontrar recursos útiles y relevantes cuando buscamos información médica ya sea como usuarios o como profesionales
buscando a susan desesperadamente
Si Twitter llega a convertirse en una fuente de información (la información instantánea), la necesidad inmediata será encontrar esa información. Se puede recurrir al buscador de twitter integrado o no en la barra de Firefox, pero una idea mejor es combinar los mejor de los dos mundos es decir buscar de forma simultanea en Internet con Google y

en los diferentes twitts de los usuarios de Twitter. Ahora se puede hacer gracias a la extensión para Firefox, llamada greasemonkey y este script. Una vez instalado se puede hacer la búsqueda en Google con los resultados de la figura
Otra aplicación interesante es Pubget, que como su creador dice es lo mismo que la famosa base de datos PubMed pero en el que se consiguen los PDFs directamente. Es decir uno hace la búsqueda y puede acceder con un clic de ratón a los artículos en formato PDF, siempre calro que estes subscrito o tu institución llohaga por ti. La idea en si aunque practica no es novedosa, ya hace años que Santiago Mola diseño PubGle que parte del mismo concepto y es que Santiago es un visionario que cuando apenas se iniciaba la web 2.0 ya nos hablaba de lo importante de la sindicación de contenidos.
tenyiarsol
En el décimo aniversario de Google es de justicia reconocer lo que este buscador nos ayuda a los médicos en el devenir diario, especialmente a los de atención primaria. Aunque no se le reconoce Google es en la mayoría de las ocasiones, la puerta a Internet y juntos constituyen el paradigma de lo que deber ser la fuente de información ideal del medico clínico atareado.
Rápido, fácil de utilizar, relevante, ubicuo, barato, comprensible, exhaustivo, cercano, valido son calificativos que se le pueden asignar y que hacen que Google sea una herramienta cada vez más utilizada. Se puede pasar consulta o trabajar en un hospital sin utilizar muchas pruebas y herramientas diagnósticas, pero cada vez menos se puede pasar sin utilizar Internet y su puerta de entrada Google, hay días que el que suscribe lo utiliza más, que el fonendoscopio
Aunque se frustro la esperanza de un Google sanitario como anunciaba Giustini en su editorial del BMJ, la relación de de este motor de búsqueda, y otros servicios de la misma empresa, con la medicina es fructífera y amplia. Google se ha utilizado para diagnosticar, en estudios de epidemias y en la toma de decisiones de salud publica, para encontrar información destinada a pacientes, para desarrollar buscadores personalizados, para crear historias clínicas personales y sobre todo para buscar información sobre salud y medicina.
Una búsqueda en pubmed -¿rivales?- nos da más de quinientos artículos en los que aparece el termino google (el primero es del 2001, la distribución por años y revistas que los publican se puede ver en la figura)
Muchos de estos artículos son revisiones sistemáticas o meta-análisis, en los que Google se utiliza como una herramienta más para completar la exhaustividad en la búsquedas de ensayos que estos estudios requieren. En otros casos la aparición del término se debe a artículos que exploran la nuevas tecnologías en medicina. Un número no despreciable son fruto de la preocupación de los profesionales por el uso de Internet como fuente de información por parte de los pacientes.
Sorprende sin embargo, la escasa literatura que explore la capacidad de google para buscar información que satisfaga las necesidades de esta y apoye la toma de decisiones, durante la consulta médica. La herramienta más utilizada de facto en las consultas médicas es olvidada por los que en teoría deberían saber sobre la gestión de la información y el conocimiento. Muchas bibliotecarias danone (por lo caducadas, no por el cuerpo) y muchos gestores gastan cantidades ingentes en bibliotecas virtuales que luego no funcionan -o incluso abandonan- Desprecian así una herramienta gratuita que es ya el futuro por donde pasa la resolución de las preguntas que surgen en la práctica clínica.
Como relatan unos médicos generales aussies en su pagina-blog ya hay una GBM o Google Based Medicine
lo sabras cuando lo veas
Esta es la frase que resume el nuevo buscador Searchme, nuevo e impresionante en el que destacan dos características especificas: la primera es la de devolver los resultados en formato visual es decir que se ven directamente las páginas encontradas en formas de imágenes que se pueden hojear como si de una realidad virtual se tratara, al estilo del Itunes.

La segunda es que divide los resultados en categorías que aparecen sobre la marcha de acuerdo al término de búsqueda ingresado, de tal forma que podamos elegir una categoría especifica y así lograr un resultado más ajustado. Por ejemplo si escribo virus en la caja, Searchme antes de la búsqueda me muestra varias categorías que van desde software hasta email, pasando por enfermedades. 
