Etiquetado: privacidad
mi carpeta de salud (VIII)
a partir de este año , las personas que tienen acceso a las historias clínicas realizadas por sus medicos también podrán acceder a la auditoria del rastro de quién ha visto sus datos
La historia clínica debería contener sólo registros ciertos, compasivos, honrados y prudentes con el paciente y ser siempre accesible al paciente
ser siempre accesible al paciente, constantemente, cuando quiera. Desde luego, lo mínimo es tener comunicación instantánea de quién, cuándo y porqué ha entrado en la historia. En un ejemplo, el paciente está en la sala de espera de urgencias hospitalarias por una herida por navaja, en una agresión callejera. Si alguien consulta su historia clínica antes de entrar a consulta, debería llegarle al paciente un aviso por mensajería instantánea de forma que supiera sin dudas qué médico está consultándola. ¿Por qué no? Lo mismo debería suceder si el paciente está de baja y el médico inspector accede a su historia clínica. ¿Por qué no?
Mi carpeta de salud (VI)
Implicaciones en la privacidad de la búsqueda de información en la Web
En abril de 2014, Timothy Libert, un joven investigador de la Universidad de Pennsylvania, diseño un programa informático llamado webXray que le permitía analizar los resultados de búsquedas sobre enfermedades. Encontró los resultados sorprendentes y ahora se han publicado como artículo en el numero de marzo de 2015 de la revista Communications of the ACM (Association for Computing Machinery).
Cuando se hacen búsquedas sobre salud y enfermedades se generan datos que son recogidos por una serie de entidades que no están sujetas a regulación o supervisión. Esta información sobre la salud pueden ser, sin saberlo el usuario, mal utilizada por algunas empresas, vendida a otros, o incluso robada por delincuentes.
Básicamente lo que se hace este estudio titulado Privacy Implications of Health Information Seeking on the Web (Libert T .Communications of the ACM, 2015; 58 (3): 68-77) es investigar los riesgos para la privacidad de las personas que visitan páginas web relacionadas con la salud. Se analizaron un total de 80.124 páginas, obtenidas de los primeros 50 resultados que arrojaba un buscador genérico como Bing al interrogarle con los términos de que correspondían a 1.986 enfermedades comunes. Estas páginas fueron analizadas para detectar la presencia de peticiones (http) de terceros e investigar qué proporción de las URIs contenían información específica relacionada con alguna enfermedad, tratamiento o síntoma médico. Ambas suponen un riesgo para los usuarios en forma de identificación personal y/o discriminación ciega.
Del total de las mas de ochenta mil paginas únicas que fueron analizadas, el 91% presentaban peticiones de terceros (se puede ver la distribución por categorías en la figura) . El análisis de las URIs reveló que el 70% de contenían información 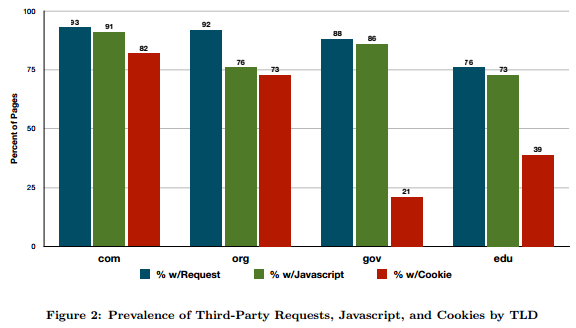 que podría desvelar algún problema medico. En las cadenas Referer aparecía información exponiendo condiciones específicas, tratamientos y enfermedades.
que podría desvelar algún problema medico. En las cadenas Referer aparecía información exponiendo condiciones específicas, tratamientos y enfermedades.
ealt
Este riesgo real en forma de identificación personal de las paginas que uno visita y la segregación de la población en grupos según las información recabada de los sitios que ha consultado -discriminación ciega- no esta contemplado por 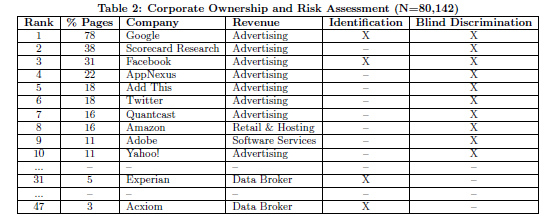 muchas organizaciones gubernamentales o no, que exponen información de sus usuarios, dejándolos desprotegidos ante tales riesgos, sin saberlo estos y a veces ni siquiera la misma organización. Por ejemplo, el buque insignia de la reforma Obama una página creada ad hoc healthcare.gov donde millones de estadounidenses se han inscrito para recibir atención sanitaria, envío información sanitaria personal a un número indeterminado de sitios web de terceros. La información que se enviaba incluía código postal, nivel de ingresos, la condición de fumador, estado de embarazo y más.
muchas organizaciones gubernamentales o no, que exponen información de sus usuarios, dejándolos desprotegidos ante tales riesgos, sin saberlo estos y a veces ni siquiera la misma organización. Por ejemplo, el buque insignia de la reforma Obama una página creada ad hoc healthcare.gov donde millones de estadounidenses se han inscrito para recibir atención sanitaria, envío información sanitaria personal a un número indeterminado de sitios web de terceros. La información que se enviaba incluía código postal, nivel de ingresos, la condición de fumador, estado de embarazo y más.
Aunque el vídeo es muy ilustrativo , vamos a intentar explicarlo de una forma sencilla, y esperamos que correcta: Cuando quiero acceder a una página web y escribo su dirección hago una petición o request (en inglés, request significa pedir, solicitar). La acción de escribir una dirección cualquiera en la línea de URL de tu navegador, se traduce en solicitar un determinado fichero a un servidor, o dicho en la jerga técnica, se le hace un request al servidor.
Por ejemplo, si yo escribo o accedo a través de un buscador a:
http://www.tumedico.com/temas/herpes_genital.htm
es como si yo estuviera pidiendo al servidor donde se aloja esta página que me la envíe. Esta petición se traduce en el servidor como
GET /temas/herpes_genital.htm HTTP/1.1
Una vez que se ha solicitado, el servidor web envía un archivo sencillo tipo html que contiene el texto de la página, así como un conjunto de instrucciones que indica como presentar la información y otras que indican al navegador web cómo descargar elementos de estilo adicional como imágenes u otros archivos. Es decir en este archivo se incluyen ordenes de hacer una nueva petición al servidor para que descargue un archivo, una imagen de un logo, por ejemplo.
El problema es que muchas veces esta petición en lugar de hacerse a ese servidor con el que estamos interactuando, es a otro servidor de otra organización o empresa. Es lo que se llama peticiones de terceros y básicamente lo que hace es pedir y descargar elementos como imágenes, javascript o las famosas cookies.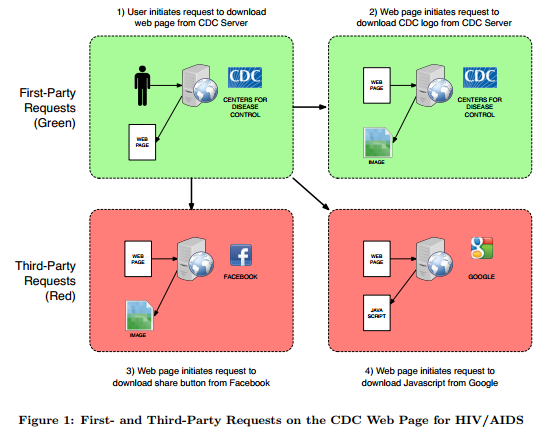
Es lo que pasa con los típicos iconos “me gusta” o “compartir” de Facebook o Twitter que aparecen en las páginas. Los usuarios no son conscientes de tales solicitudes, y que en cierta forma están contactados con Facebook, ni que este sabe la página que están viendo ya que estas empresas reciben información como esta:
Referer: /temas/herpes_genital·htm
El campo Referer revela que el usuario está consultando una página sobre herpes genital. Vinculando información de otros campos como User-Agent, o la dirección IP del usuario, es posible que las empresas como Google y Facebook identifiquen a las personas que están consultando páginas sobre herpes genital
Un identificador de recursos uniforme o URI —del inglés Uniform Resource Identifier— es una cadena de caracteres que identifica los recursos de una red de forma unívoca. Los URIs (Uniform Resource Indentifier) son la forma estándar de nombrar los destinos de los enlaces para herramientas tales como los navegadores web. Algunas personas usan el término URL como sinónimo de URI, aunque técnicamente no son los mismo porque las URLs son parte de los URIs que abarcan también a los Uniform Resource Name.
La cadena http://www.tumedico.com/temas/herpes_genital.htm es una URL y también un URI por eso para nuestro caso podemos igualarlo y entenderlo como las “clásicas direcciones web”
